Consider the following three servers from different zones with the respective share in their “home” zone, all at the same netspeed setting.
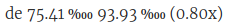
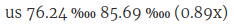
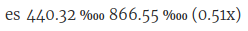
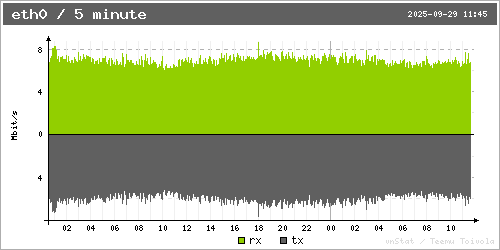
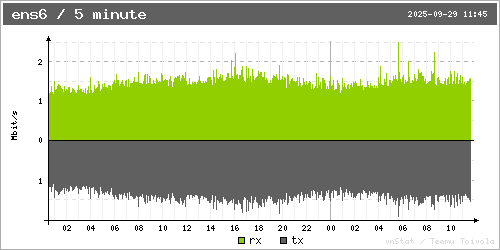
Now guess for each of them which of the following bandwidth usage graphs it matches (the server in the USA has IPv4 only, the others have IPv6+IPv4 in the following figures):
Solution: First graph is for the USA, second is for Spain, third is for Germany.
So while the servers in the USA and Germany have approximately the same share of the overall netspeed in their respective zones, and roughly the same share of the DNS requests from their respective own zone, the one in the USA is seeing roughly six to seven times the amount of traffic of what the one in Germany sees (and that is not even properly discounting that the graph in Germany also includes IPv6 traffic, while the one from the USA does not).
Or comparing Spain with the other two, it has almost six times the DNS request share from its own zone than the other two servers see from their respective zones. Yet, it sees about double the amount of traffic that the server in Germany sees. At the same time, the server in the USA sees roughly about three times as much traffic as the one in Spain.
That obviously does not take into consideration traffic from other zones hitting the server, but that is very much negligible in comparison to the differences between zones discussed above.
The situation regarding traffic from outside the zone is different in other zones, e.g., consider the following server:
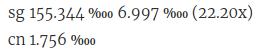
The permyriad value for the server’s own zone is about 88 times the permyriad value for the first foreign zone. But looking at the actual traffic, there’s almost eight times as much traffic from China than there is from Singapore. Which isn’t surprising, because 0.01756 % of an estimated 1,022,000,000 Internet users in China is more than 1.55 % of “only” 5,369,000 estimated Internet users in Singapore.
So the point is, zones are extremely diverse, and just because two servers in different zones have the same netspeed setting doesn’t mean at all that they will be seeing the same amount of traffic. E.g., a user from China in this very forum reported that they are seeing double-digit, sometimes even triple-digit Mbit/s traffic with the same 512 Kbit setting that you use. And I guess you do not see 10 Mbit/s or even more of actual traffic on your server in Belgium at 512 Kbit, or do you?
E.g., Belgium currently has about 22 active IPv4 NTP servers, while France has 209 of them.
Ok, you might say, France is bigger, and has more people, so they simply have more servers obviously. But if you compare the number of Internet users (an estimate obviously) per server, then France has about 267500 users per server, while Belgium has almost double that many users per server (approximately 496400). So any other factors aside, just based on those numbers, I would expect a server in Belgium to be hit by noticeably more traffic than a server in France at the same netspeed setting, just because almost twice as many users are potentially accessing it.
To sum up, it doesn’t need the assumption of bugs in the pool’s algorithms to see why a server in Belgium might be hit by much more traffic than a server in France at the same netspeed setting. Though to pinpoint exactly what contributes to that difference is somewhat difficult because there are just so many factors at play simultaneously.