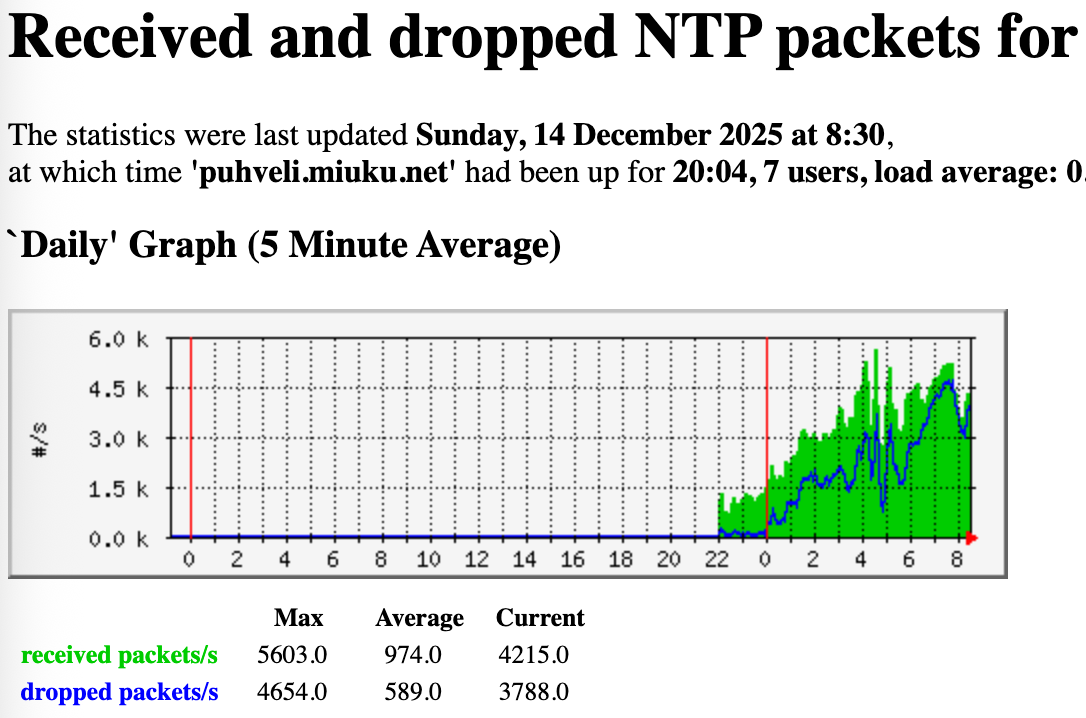
I came to check upon my servers and found out that my VPS in Philippines is suffering too many requests, even beyond the provided bandwidth allocation (30 Mbps). What’s worse, the incoming requests aren’t subsiding after I lowered the speed or dropped completely to monitoring only mode which usually works elsewhere. Stopping chrony makes it even worse. The network graph was suspiciously flat before that too, usually there are some spikes of traffic at certain whole minutes but not here. Did someone just hardcode IP of my server to config of whole ISP? But it’s not one ISP, it’s several from quick check of the most abusive source IPs. Look at it:
chronyc clients -p 10000000
Hostname NTP Drop Int IntL Last Cmd Drop Int Last
===============================================================================
dsl.49.148.156.90.pldt.n> 173041258 12413 -5 -5 0 0 0 - -
customer.mnlaphl1.pop.st> 26012634 51889 -5 -5 0 0 0 - -
152.32.90.151.convergeic> 11079607 24249 -5 -5 0 0 0 - -
143.44.164.103-rev.conve> 610531294 35896 -5 -5 0 0 0 - -
221.121.96.12 585883306 39976 -5 -5 0 0 0 - -
222.127.248.227 48055551 6812 -5 -5 0 0 0 - -
dsl.49.148.143.232.pldt.> 178630730 62955 -5 -5 0 0 0 - -
216.247.24.180 30503932 35313 -5 -5 0 0 0 - -
112.208.68.234.pldt.net 89931592 45527 -5 -5 0 0 0 - -
119.94.108.190.static.pl> 245991730 35968 -5 -5 0 0 0 - -
dsl.49.149.109.74.pldt.n> 26105255 26588 -5 -5 0 0 0 - -
138.84.126.219 36496398 51731 -5 -5 0 0 0 - -
126.209.18.242 33968244 21940 -5 -5 0 0 0 - -
customer.mnlaphl1.pop.st> 12873982 42708 -5 -5 0 0 0 - -
150.228.189.18 19686200 36567 -5 -5 0 0 0 - -
165.99.250.25 87288148 19445 -5 -5 0 0 0 - -
173.87.29.120-rev.conver> 21062944 36029 -5 -5 0 0 0 - -
58.69.163.116.pldt.net 35736402 33794 -5 -5 0 0 0 - -
138.84.115.193 56171978 35733 -5 -5 0 0 0 - -
dsl.49.144.194.107.pldt.> 46044192 34481 -5 -5 0 0 0 - -
138.84.114.216 10480342 57686 -5 -5 0 0 0 - -
120.28.194.245 11423169 22707 -5 -5 0 0 0 - -
180.190.7.125 40073423 17689 -5 -5 0 0 0 - -
dsl.49.148.227.91.pldt.n> 18104657 35843 -5 -5 0 0 0 - -
196.79.158.136.convergei> 20587174 54135 -5 -5 0 0 0 - -
32.83.158.136.convergeic> 11273016 31335 -5 -5 0 0 0 - -
120.28.194.14 62105389 21907 -5 -5 0 0 0 - -
143.44.196.16-rev.conver> 15534873 58877 -5 -5 0 0 0 - -
139.135.192.168.converge> 101897193 10607 -5 -5 0 0 0 - -
dsl.49.145.208.242.pldt.> 25932534 24984 -5 -5 0 0 0 - -
dsl.49.149.205.220.pldt.> 180861011 57512 -5 -5 0 0 0 - -
120.28.199.153 14405156 28541 -5 -5 0 0 0 - -
112.200.160.90.pldt.net 225447547 3134 -5 -5 0 0 0 - -
103.161.61.77 376803247 10680 -5 -5 0 0 0 - -
150.228.189.242 15093627 22217 -5 -5 0 0 0 - -
139.135.77.238 50047575 20703 -5 -5 0 0 0 - -
dsl.49.149.99.232.pldt.n> 12527978 47221 -5 -4 0 0 0 - -
203.177.193.196 38676294 22509 -5 -5 0 0 0 - -
103.91.142.72 24573736 39882 -5 -5 0 0 0 - -
126.209.13.45 89343040 16204 -5 -5 0 0 0 - -
180.195.158.118 28361202 18941 -5 -5 0 0 0 - -
222.127.169.33 27864001 31288 -5 -5 0 0 0 - -
Normal traffic

After turning down the netspeed:

After putting server in monitoring mode and stopping chrony: