Normally you only get monitors assigned that score you good.
Those will become active for your server.
All others will be ignored.
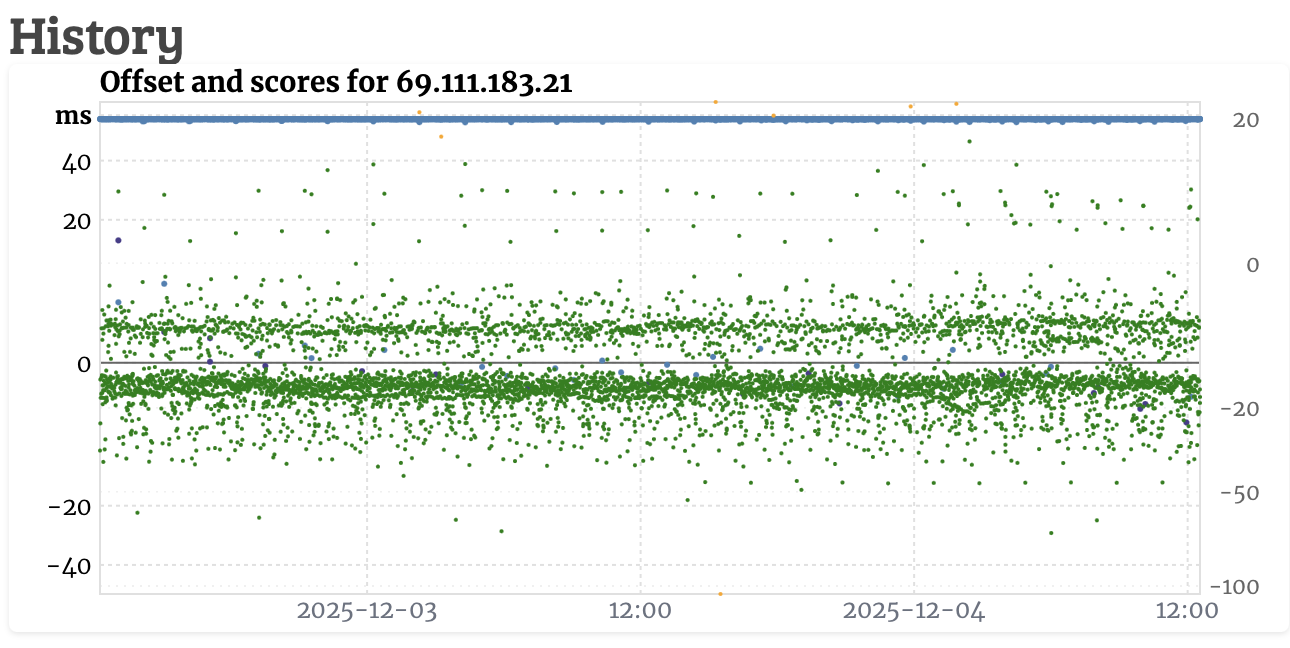
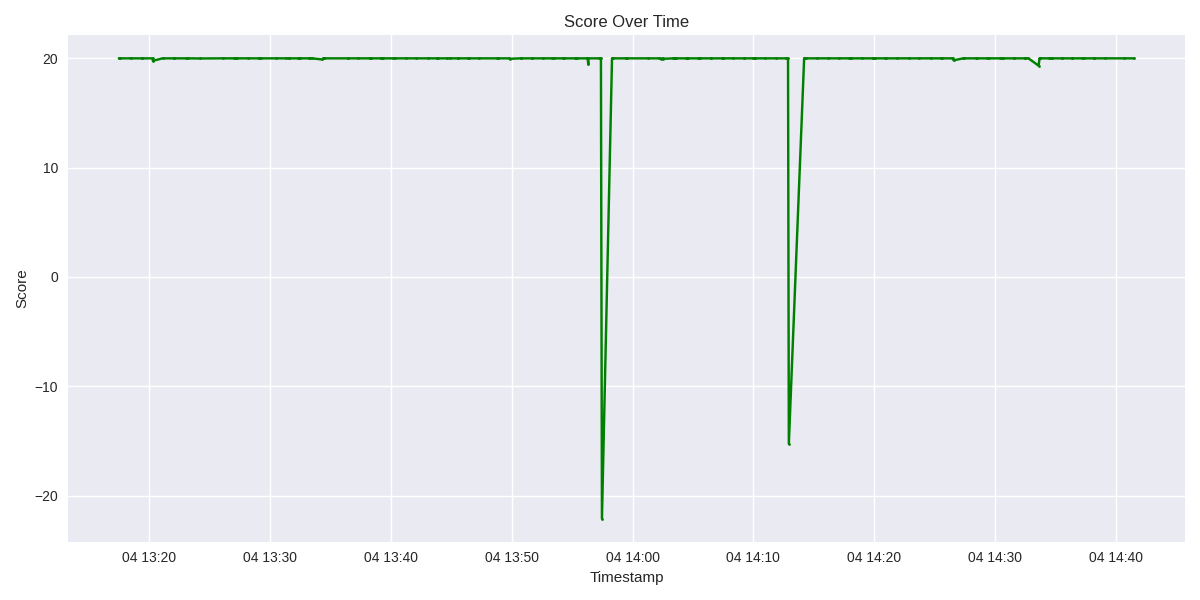
Your score only drops when active monitors monitor you badly, typical when your server is online this won’t happen…except when your are working on something that it can’t be reached or your server is ticking wrongly.
Other then that, your score will be perfect and monitors that see your server are selected.
When you add a new server to the pool, it also takes some time for monitors are assigned to your system.
From what most of us see, this system works quite well.
Keep in mind, only the ACTIVE monitors determine your score, all others have NO impact, regardless their score.
And yes, active monitors can be added when candidates score you better.
And yes, active monitors can be removed when actives score worse then candidates.
Normally only the best monitors are assigned to your server. It’s an algorithm that determines this automatically.
The task of a monitor is to see if you are online and ticking correctly, the ms you see is a ping-time not important. A monitor with a higher ping can be very good for your server, while a close monitor may not even reach you.
Also know, the monitors themselves are also checked by the system and internally by the monitor-deamon itself, before it started checking other servers, the monitor checks the system-time of the machine, when it’s off, it will stop checking others.